毫无疑问,基于AI的合成语音正在包围我们的生活——银行、快递、运营商等服务热线十个有九个是AI;几乎所有的智能电器都为你精心挑选了御姐音和清朗男音的智能语音包;打开地图导航APP,数十个明星将“亲自”为你指路…… 但在有声小说、影视配音、虚拟主播等场景,笨拙且毫无感情的合成音色难以增强文本生动性和感染力,难以为用户营造沉浸式的听觉体验;而伴随大模型时代的到来,更自然、更智能的人机交互正在发生,人们越来越需要机器给予“情感”回馈,更富表现力、更具情感色彩的合成音色正成为新的期待。 云知声深耕AI语音交互领域多年,推出包括音库定制、声音克隆等多种TTS解决方案。近日,云知声TTS再上新,拓展9个全新音色,更实现了接近真人表达的十余种情感风格,能够满足虚拟人、人机对话、有声读物、短视频制作、电话客服等多种场景需求。 
为声音注入情感,语音真实感全面升级 云知声情感合成音色支持开心、生气、难过、害怕、厌恶、吃惊等十余种情感,在情绪表达、风格拓展、音色效果等方面实现新突破,充分满足用户的个性化需求。 多情绪多风格 无论你想要喜怒哀乐,还是正式、悠闲、亲切的口吻,云知声情感合成都能完美契合,可适用于不同情境下的不同语意表达。 音色效果自然流畅 无论是语句的起伏、停顿,还是语调的适时转换,云知声情感合成都几近真人,带给用户的不再是机械冰冷的声音,而是更流畅舒适、更具人性关怀的听觉体验。 音色可定制化 无论你是希望拥有特定人物的声音,例如名人、明星,还是具备特定特征的声音,如男性、女性、老人、少年,亦或者是想要特定情境的声音,如客服场景、有声阅读甚至是rap,云知声情感合成都能够满足你的需求。 以声传情,云知声是如何做到的? 如何让声音富有情感和表现力,一直是语音合成技术的一大难点——首先,生成富有情绪的语音合成需要大量的情感合成数据作为训练样本,而此类数据的获取又相对困难;再者,情感通常和语境紧密相连,不同语境下,同一段话所表达的情感可能完全不同,所以即使有了大量的情感合成数据,也并不能保证合成语音的稳定性。 云知声给出的解决方案是,基于超大规模数据训练得到端到端声学模型和神经网络声码器等基础模型,然后再通过小规模的情感数据进行自适应训练,在自适应训练阶段,加入情感表征和说话人表征——加入情感表征是为了让机器生成的声音更具有表现力;而引入说话人表征则是为了让机器生成的声音更具个性,使得听起来像是由具体的某一个人发出的。这样做的目的,就是为了保证在让机器生成的声音拥有情感的同时,还能保持声音的稳定性和连贯性。 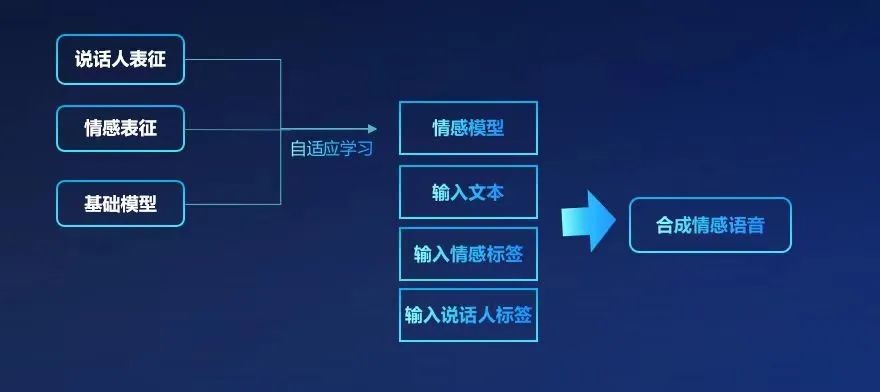
如此一来,在给定一段文本,同时指定一个情感标签或说话人标签后,机器就能够生成带有相应情感色彩的语音。举个例子,当我们指定了"高兴"的情感标签和"年轻女性"的说话人标签,那么机器就能自动生成一段由一个高兴的年轻女性说出的语句。 郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
|










